
で、何をやったの?3行で
自前の3Dキャラをぐるっと回して画像を撮影
Textual Inversion (EmbedingやHypernetwork) で学習
オリジナルキャラっぽい画像を生成
で、どうなったの?見せて
これを学習したら

これが

こうなりました。

プロンプトの吟味もほどほどでほとんど厳選していないので、もっといい絵も出せるかもしれません。呪文はEmbeddingタグを足した以外は一緒です。
キャラだけの学習のつもりでいましたが、結果的にセルルックっぽいスタイルも同時に学習されている感じがします。あとポニーテールが短い。
ちょっとそれっぽく呪文やら何やらを整えて、img2imgで邪魔なものをそれとなく削ったりして調整したものが以下のものです。楽々一発ぽんぽんではなかったのですがそれなりのクオリティにはできそうでした。

目的と目標
私は絵が描けないので、マンガとか難しいなあと思っていたのですが、仮に安定した描写でオリジナルキャラを出力できるならぺたぺた作成できるのでは?と思った次第です。そもそもの3Dキャラをポージングしてぺたぺたするという方法もあるのですが、意外にもキャラのポージングを作成するのは結構時間がかかり、かつレンダリングもなんやかんやで時間がかかるということで雑になんとかならないかなあという雑な気持ちでやってみることにしました。
目標としては3Dモデルの特徴を十分に理解した絵がいろいろなポージングでおおよそ同じスタイルの画風で出力できるといったところでしょうか。
画像生成AIの準備
AI画像生成はAUTOMATIC1111さんのstable-diffusion-webuiを用います。このあたりの基本的な導入方法や使い方はGIGAZINEさんにだいたい載っているのでそれを参考にして整備してください。8GBのGPUがあればだいたいなんでもできます。私はちょっと古いのですが、GTX1070を使っています。
今回のターゲットはマンガっぽい二次元絵なので、モデルデータは二次元絵にお強いwaifuを利用します。私は現状最新っぽいv1.3を利用しました。自キャラがリアル調で、最終出力もリアル調にしたい場合は元々のStable Diffusionのモデルを利用するのがよいかもしれません。
ひとまず、AI側の準備はこれでいいことにしましょう。
学習用画像の用意
オリキャラをBlenderとかなんかでぐるっと回転させて撮影するだけです。今回は8方向、全体と顔のみの2パターンで撮影し、計16枚の画像を用意しました。画像数が多いほうがいろいろな体勢やカメラアングルに対応できる気がしますが、今回はお試し的な意味もあり、楽をしています。
口を開けている状態が想像しやすいように口開け、ほぼAポーズで雑に撮影しました。学習の都合から背景は黒抜きか白抜きがオススメです。黒い輪郭線がしっかり分かったほうがいいだろうと思って一度グリーンバックにしてみたのですが、そのときはタタミや草原と勘違いされて面倒なことになったので、グリーンバックはやめましょう。
画像は1対1のサイズがベストです。というかマストかもしれません。








画像は適当なフォルダにまとめて入れておきましょう。
学習用タグの用意の前準備
学習には画像とその画像が何をしているのかを表すタグが必要です。厳密にはタグじゃなくてワードでもいいのですが、waifuはdanbooruを学習しているということもあり、今回はdanbooruベースで作成します。
ここで画像生成AIを起動すべくwebui-user.batをダブルクリックするのですが、その前に画像解析にdanbooruタグを使うことやwaifuモデルを使うことをバッチに書いておきましょう。
set COMMANDLINE_ARGS=--ckpt ./models/Stable-diffusion/waifu.ckpt --deepdanbooru私の場合はwaifuのモデルはwaifu.ckptにしているので、上記のようになっています。waifu以外で学習させる場合は違うモデルを設定しましょう。
起動したら、さっそくTrainタブを開きたいんですが、その前にSettingタブを開きます。画像を解析してタグをつけてくれるdeepdanbooruはデフォルトではアンダーバーやらを伴ってタグを作るのですが、それだと正しく利用できないためそれを外す設定をします。
Interrogate Options内の上のチェックを外し、下の二つにチェックを付けましょう。
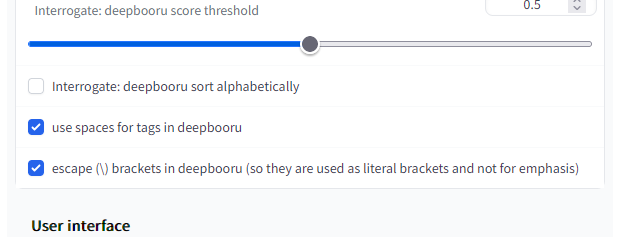
上のチェックはタグのソートですが、画像生成AIでは前にあるほどタグの力が強くなります。アルファベット順にソートされると都合が悪いので外しておきます。
下の二つは要するにアンダーバーをスペースにかえるぞというのと括弧とかはバックスラッシュでいい感じにするぞという話です。とりあえず雑になんかいい感じにしてくれるんだと思えばいいでしょう。
あとTraningのとこのやつもチェックしておきます。
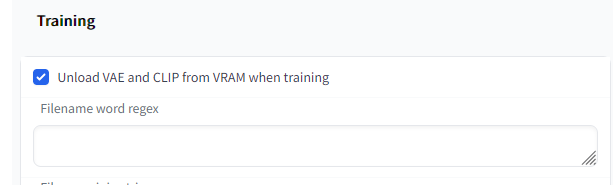
メモリが十分あればたぶんこのチェックは不要なのですが、付けておけば安心でしょう。
上方のApply settingをクリックして設定を保存します。保存しないとダメなので気を付けましょう。
学習タグの用意
それではTrainタブに移動して画像とタグを準備しましょう。Trainタブ内のPreprocess imagesタブを選択します。ここでは学習用の画像とデータを作成できます。今回はすでに1対1画像を作ってありますが、画像のサイズの変更や左右反転画像を作って学習データを水増すなどのこともできます。オリキャラが左右非対称の場合は反転画像は利用できないので注意してください。
先ほどの画像を用意したフォルダをインプットのディレクトリに、作成先をDestination directoryに記入します。今回はdeepbooruでタグをつけたいので、その部分にチェックを入れてPreprocessを実行します。
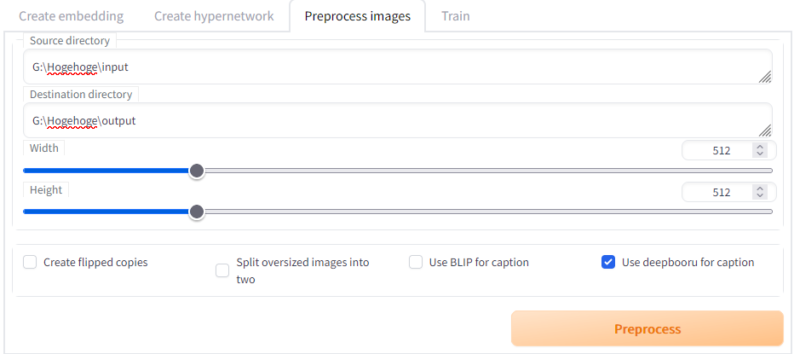
すると出力先フォルダにサイズ調整された画像と謎のテキストファイルができます。画像と同名のテキストファイルがある場合、テキストの中身を学習用のタグとして利用するという仕組みになっているので、このテキストの中が重要です。
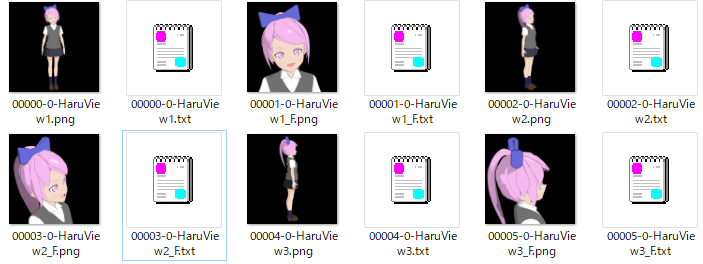
テキストを一つ開いてみてみましょう。私の画像では以下のようになっています。
black background, 1girl, solo, open mouth, shirt, pink hair, collared shirt, pink eyes, letterboxed, bow, smile, white shirt, bangs, upper bodyこのキャラクターを学習させたいので、このキャラクターの特徴的な要素はあえてここから省きます。これは記載されているタグ+オリキャラタグ=画像のタグとなってほしいためです。あとなんか明らかにおかしいタグも合わせて消しておきましょう。
black background, 1girl, solo, open mouth, shirt, collared shirt, smile, white shirt, bangs, upper body1girlもキャラの要素と言えばキャラの要素なのですが、ふわっとした要素なのでまあ残しておいていい気がします。bow(髪飾り)は重要な要素なのでキャラに内包させました。服装に拘りがあるキャラの場合はそのあたりのタグは省いておいた方がいいでしょう。
すべてのテキストデータを確認していらなそうなものは省きます。余力があれば前述のように強い要素は前に出しておくといいでしょう。1girlやupper bodyが強い要素、black backgroundは弱い要素かなと思います。今回の学習では面倒なのでやってません。あと明らかにsmileなのにsmileタグが入ってないとかの場合は足しておいた方がより正確な学習ができると思います。
これで学習データができました。次からが実際の学習です。
Embeddingの学習
Embeddingはかなり強力な追加学習です。何が強力って元絵をぶっ壊す勢いで効果が発揮されます。でも毒も薬も使いようということで、いい塩梅で学習させられればいい感じなるはずです。
↓なぜかいつの間にかに髪の色が黄色に学習されるの図。


学習途中のデータも保存されるので、変な学習になってもそこまで気にしなくて大丈夫です。
さてTrainタブのCreate embeddingを開きます。名前は私の場合はハルちゃんなのでmyharuembとしました。embedding利用時の呪文になりますので、一般には意味のない言葉にしておいた方が無難かと思います。
Initialization textは初期化文字列なのですが、学習されていないモデルで動かした場合の代替タグらしいです。そもそも論なのですが、waifu.ckptで学習したembeddingは他のモデルでは利用できません。waifuがバージョンアップした場合も同様です。そう言った場合に変な学習データを読んで画像を破壊する代わりに違うタグとして扱うくらいの気持ちで雑に私は理解しています。まあ、1girlとか入れておけばOKでしょう。
ベクターは複雑さです。大きいほど複雑な要素を学習できます。その代り過学習しやすくなり、高品質な学習データが必要になります。スタイルの学習なら1とか4とかで多分十分ですが、キャラは16とか32とかあったほうがいいでしょう。そんなに試してないので実際のところは不明です。本家っぽいところでは8でやってみたらしいですが、微妙なクオリティだった気がするので、雑に32。なんかキリがいいし。
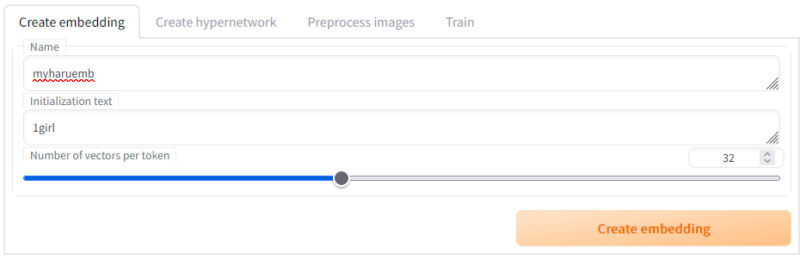
Createを押すとembeddingsのフォルダに作成されます。さあ学習を開始しましょう。
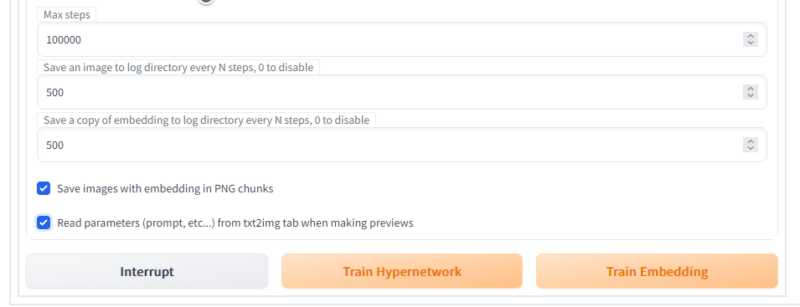
Trainタブへ行きます。Embeddingに今作ったモノ、Hypernetworkは今回は空白、Learning rateは0.00005にします。デフォは0.005なのですが、体感ではちょっと早い気がしたので下げました。前述のように途中のデータは出力されるので学習が遅い分にはあまり気にする必要はありません。ただ時間がかかるだけです。正直0.00005は下げ過ぎた気がするので、0.0005あたりがいいかもしれません。
Batch sizeは1、Datasetは先ほどの学習画像セットの出力フォルダ、Prompt template fileはデフォルトではスタイルの学習のものになっているのでsubject_filewordsにします。
マックスステップ100000は正直過多ですが、途中で止めても学習データは出力してくれるのでそのままでいいでしょう。最後のRead parametersはチェックを入れます。学習途中、今回の場合は500ステップごとに画像を出力してくれるのですが、この出力画像の生成呪文をtxt2imgタブに書かれているものを利用して出力してくれます。これをやらないと適当な呪文とシード値で経過画像が出力されるので、うまく学習できているのか分かりにくくなってしまいます。必ずチェックしましょう。
Train Embeddingを押す前に、前述のtxt2imgのページを埋めておきましょう。Seedは必ず固定にしておきます。promptは学習用データの削減前のプロンプトに自分のembeddingの名前のタグを足したものにするとたぶんいい感じです。embeddingの名前だけだと、その他の1girl要素やポーズ要素が足りなくなるからです。
というわけでプロンプトは以下の感じにします。
1girl, solo, full body, black background, pink hair, skirt, hair bow, open mouth, pony trail, blue legwear, socks, shoes, shirt, standing, pink eyes, pleated skirt, short sleeves, brown footwear, short hair, bangs, school uniform, white shirt, myharuemb
理想的にはmyharuemb内にポニーテイルやピンク髪要素が内包されているはずですが、記載があったほうが安定するので、付けておきました。純粋に埋め込みデータのみの力を見たいときははずしておいてもいいかもしれません。実際、学習後にこれらのタグを外して生成した場合でもポニーテールっぽい感じにはなりました。
ネガティブプロンプトはいれておくと安定するので、よくあるテンプレートを入れておきましょう。
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name
Sampling Stepは40くらいに少し増やし、Seedは前述通り-1以外にしておきます。後のパラメータはお好みですが、そのままで特に問題ないでしょう。
あとは再びTraningタブに戻ってTrain Embeddingを押すだけです。しばし待つのみ。
学習途中のデータがtextual_inversionフォルダの日付の場所に出力されます。学習がうまくいっていないと明らかにおかしなノイズデータみたいになったりするのでそういう場合はいったんやめて、ちょっと画像のプロンプトとかを見直してからやり直しましょう。

同じフォルダに途中段階のembeddingも入っています。これをコピーしてリネームし、ホームディレクトリのembeddingsに置くことで利用したり、途中から学習を再開したりできます。途中までうまくいっていたのになあ、という時は試してみましょう。
Embeddingの利用
embeddingはプロンプト内にタグを利用して効果を発揮します。タグはファイル名と同じです。
つまりこんな感じで利用します。
myharuemb, 1girl, solo, full body, black background, pink hair, skirt, hair bow, open mouth, pony trail, blue legwear, socks, shoes, shirt, standing, pink eyes, pleated skirt, short sleeves, brown footwear, short hair, bangs, school uniform, white shirt,
以下それぞれ未使用、前タグ、後ろタグで出力してみました。同じシードでオリキャラのタグ以外は同じ呪文です。



前述の通り、embeddingはかなり強力です。ちょっと変えたいだけなら後ろに置いたり弱めに置いたりするといいと思います。Stable diffusionでは()を使って強くしたり、[]を使って弱くしたりできます。
以下は後ろタグにして弱め[myharuemb]、超弱め[[myharuemb]]にしたものです。


弱くなったせいかピンク髪ですらなくなっているのもありますが、前髪の特徴などをそれなりに残したまま絵としての安定感が増しているのが分かると思います。個人的にはembeddingはそっと弱めに置いてやるというのがよさそうかなという感じです。
Hypernetworkの学習
HypernetworkというのはNov(おっとこれ以上はいけない)から発想を得たチューニング技術です。この技術ではembeddingと同様にキャラやスタイルを学習できるのですが、実装上どっちかと言えばスタイルの学習に向いているような気がします。というのもHypernetworkはembeddingと違い、実行の際に用いるタグのようなものがありません。Hypernetworkを読み込んだ状態で出力されるすべてのものに影響を与えます。他のタグとのバランスを取ったり強弱をつけたりしにくいということで、スタイルよりなのかなと思っていますが、どっちでもまあ動くことは動くと思います。こっちのほうがembeddingより優しい感じの変換処理だと思います。
Trainタブ内ののCreate hypernetworkタブを開きましょう。設定はデフォルトのままでいいと思います。私はmyharuhnwにしましたが、タグとの競合とかもないので本当になんでもいいと思います。
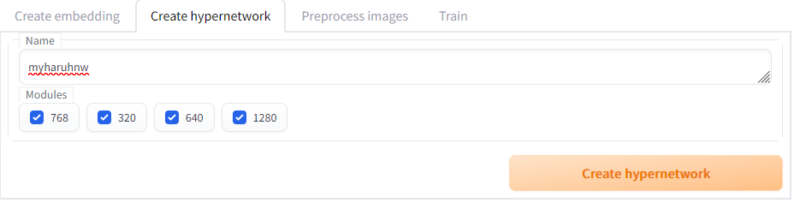
Createを押すと作成されます。
学習データについてはembeddingと同じものでいいと思います。こっちは利用時にタグがなく、タグの発生に依存しないので、キャラの要素を削らなくても実はうまくいくんじゃないかというような気もしなくもないですが、タグ情報と実際に出力された画像の差を縮めるように学習していくという仕組み上、削るのが順当かと思います。正直たぶんどっちでも実行時のプロンプトを調整すればたいして差はないんじゃないかと思います。
学習用画像はすでにあるということでさっそくTrainタブに行きます。text2imgの項目はembeddingと同様に事前に埋めておいてください。
今回はEmbeddingは空白、Hypernetworkは先ほど作成したもの、Dataset directoryはEmbedding時と同様のものを利用します。Prompt template fileはhypernetwork.txtといいたいところなのですが、これを使っているケースはあまり聞かないので、[filewords]とだけ書かれているものにしましょう。個人的には既存の用意されているものでもそれほど悪くはない気がします。
[filewords]Learning rateについてですが、今回は0.0000005を利用します。Hypernetworkの場合はEmbeddingと比べてかなり小さい値を利用することが推奨されています。学習の仕方が違うのでそうだということなので、あまり気にせず小さい値を使いましょう。私は相変わらず安全主義で小さい値を使っていますが、もう一ケタ上の0.000005くらいでもうまくいくようです。
Read parametersほげほげにちゃんとチェックが入っていることを確認してTrain HypernetworkをクリックすればOKです。
あとは寝ながら待ちましょう。私はとりあえず15000ステップくらい待ちました。
Hypernetworkの利用
前述の通り、Hypernetworkはタグで利用するわけではありません。利用するにはSettingsでHypernetworkを設定するか、X/Y plotで設定するかです。まずは一般的なSettingsに設定する方法を見てみましょう。
Stable Diffusionの項目にHypernetworkというタブがあります。これを設定すればOKです。その下にもなにやらHypernetworkの強さを決定するっぽい項目とかありますが、たぶん弱めることもできるんでしょう。今回はいじりません。
忘れずにApply settingを押して戻ります。
あとは単にいつも通りプロンプトを書いて出力するだけです。ほんとに効いてるの?って思う場合は、外して設定を保存したうえで同じシードとプロンプトで出力してみれば違うことが分かるはずです。
次にX/Y plotを使う方法です。途中経過もいっぺんに確認したいときなどに有用だと思います。オプションのほうのHypernetworkの設定はひょっとしたら外しておいた方がいいかもしれません。img2txtの下方のScriptの項目からX/Y plotを選択します。あとはX typeをHypernetworkにしてhypernetwork名を並べるだけです。
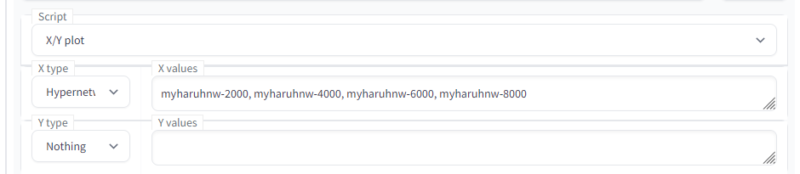
デフォルトでは最新の学習結果がつけた名前で置いてあるだけ(私の場合はmyharuhnw)なので、学習途中のデータと比べる場合は、自分でtextual_inversionの日付フォルダの中から学習データをコピーしてmodels\hypernetworksの中にペーストしましょう。
実行すると以下の感じで出ます。

Embeddingに比べるとだいぶやさしい感じの効き方をしているのが分かるかと思います。ここからもっと学習していけばひょっとしたらもっと効きが強くなるのかもしれませんが、10000以降それほど強い変化を感じなかったので、かなり収束に近いのかなという認識です。
終わりに
特徴的な部分はちゃんと見える絵を用意するというのが必須だったかなという気持ちです。ポニーテールがやや小さいのは正面絵では全く見えていないし、顔のアップでは下の方が切れているからな気がします。これぞチャームポイントと思われる要素はできる限り見える画像を使ったほうがより良い結果が得られた気がします。学習素材は大事なので適当にぐるっと回して撮影しないほうがいいでしょう。
最終的にはEmbeddingを優しくかけながらHypernetworkを適用して出力しました。合わせ技を決めてプロンプトを調整すればわりといけてる絵も出せるような気がします。絵のタッチの固定はたぶんスタイル指定でかなり安定するんじゃないかと思いますが、そもそものキャラの風貌が楽々生成とはいかなかったので、現状の学習ではマンガでぺたぺた生活は難しそうです。



Dreamboothという方法だともっと簡単な感じでキャラにチューニングできるといううわさです。ローカルで試すには結構メモリが必要ということで試せていないですが、Colabで動くらしいのでそのうちこれも試してみたいですね。
ほそぼそアニメーションとかツールとか作ってます。よろしくお願いします。
威借憶人 / Ikari Okuto
